
2023年末に行った会社での技術レビュー発表を元に、加筆、修正をした内容になっています。
2023/DEC/28
更新履歴
日付
変更内容 2024/MAR/20
修正
YMO TECHNOPOLIS
https://www.youtube.com/watch?v=28f6znYxFfM
https://www.g200kg.com/jp/docs/dic/vocoder.html
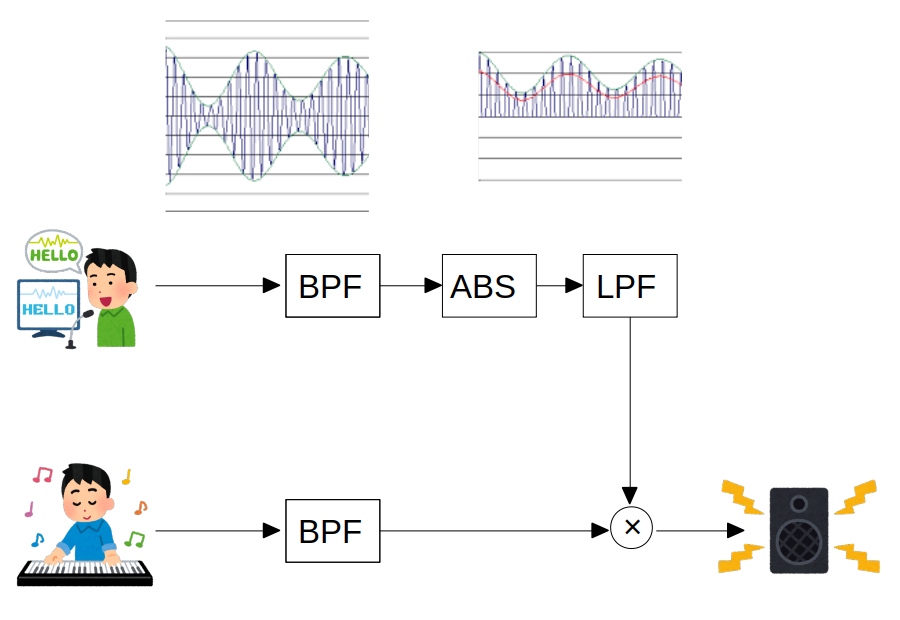
鍵盤とマイクを持ち、マイクに向かってしゃべりながら鍵盤を弾くとシンセ音でしゃべるという、いわゆるロボットボイスを作り出す機器。
もともとはベル研究所によって通信用の音声圧縮のために開発された技術である。
かつてのテクノブームの時には大いにもてはやされた。
音声を多数のフィルターで分割して特徴情報だけを取り出し、別のキャリアとなる音声に移植するというのが基本原理である。
https://faq.yamaha.com/jp/s/article/J0004413
ボコーダーの原理は、人が声を出すしくみに関係があります。
人は声帯で発生する音を口や鼻で共振させて声を出しているのですが、 この共振部は周波数特性を持っていて、一種のフィルターとして働き、多数のフォルマントを発生させています。
ボコーダーでは、マイクから入力された声からこのフィルターの特徴を抽出し、多数のバンドパスフィルターで声のフォルマントを再現しています。
楽器の音をこのフィルターに通すことによって、いわゆるロボットボイスを作り出しているわけです。
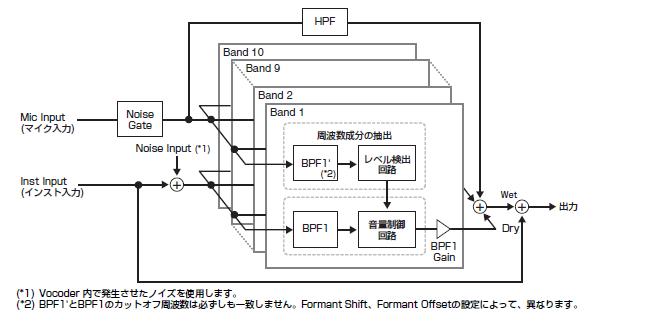
あるサウンドの周波数スペクトルのうち、基音の音高に関係なく常に同じ周波数帯に現れるピークのことをいいます。
フォルマントによって、それぞれのサウンドの音色は特徴付けられています。
フォルマントをシフトさせる(ずらす)ことにより、男性の声を女性の声に変化させるなどの面白い効果を得ることができます。
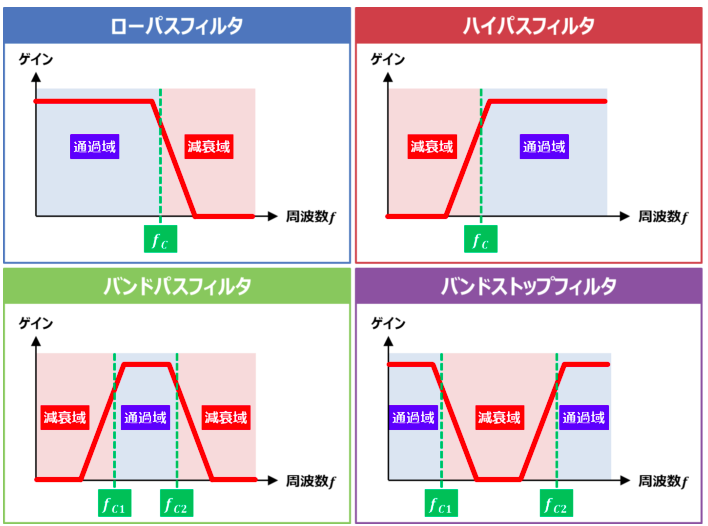
https://detail-infomation.com/lpf-hpf-bpf-bsf/
『LPF』と『HPF』と『BPF』と『BSF』の違い
https://www.g200kg.com/jp/docs/makingvst/04.html
g200kg Music & Software
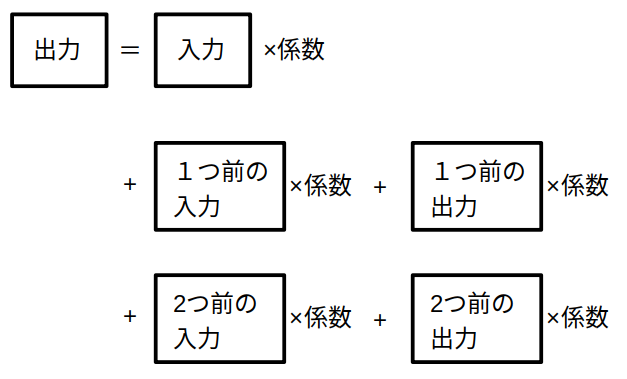
デジタルフィルタ BiQuad型
主要なパラメータは
OUT = [ IN * B0 + IN_1 * B1 + IN_2 * B2 + OUT_1 * A1 + OUT_2 * A2 ] / A0
IN : 入力 IN_1 : 1つ前の回の入力 IN_2 : 2つ前の回の入力 OUT_1 : 1つ前の回の出力 OUT_2 : 2つ前の回の出力 OUT : 出力 A0,A1,A2,B0,B1,B2: 係数
LPF, BPFの種別、サンプリング周波数、カットオフ周波数、Q値によって、係数が決まる
フィルタ箇所のコード
def filter_new( freq, Q, ftype, smp_freq ):
smp_t = 1.0 / smp_freq
w0 = 2 * math.pi * freq * smp_t
cos_w0 = math.cos( w0 )
alpha = math.sin( w0 ) / ( 2 * Q )
b0 = b1 = b2 = 0
if ftype == 'LPF':
b1 = 1 - cos_w0
b0 = b2 = b1 * 0.5
elif ftype == 'HPF':
b1 = -( 1 + cos_w0 )
b0 = b2 = -b1 * 0.5
elif ftype == 'BPF':
b0 = Q * alpha
b1 = 0
b2 = -b0
a0 = 1 + alpha
a1 = 2 * cos_w0
a2 = alpha - 1
div_a0 = 1.0 / a0 if a0 != 0 else 0
buf_i = [ 0, 0 ]
buf_o = [ 0, 0 ]
def trans( v ):
if a0 == 0:
return 0
out_v = ( b0 * v + b1 * buf_i[ -1 ] + b2 * buf_i[ -2 ] + a1 * buf_o[ -1 ] + a2 * buf_o[ -2 ] ) * div_a0
buf_i.pop( 0 )
buf_i.append( v )
buf_o.pop( 0 )
buf_o.append( out_v )
return out_v
return empty.new( locals() )
音声データは、全てメモリ上に読み込んで処理する。
処理結果は、最後にまとめてデータファイルに書き出す。
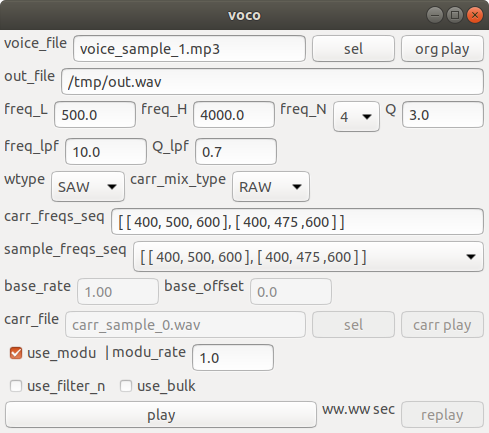
wxPythonを使用
| voice_file | 音声データファイル | |
| out_file | 出力データファイル | |
| freq_L | チャンネルのBPF最小周波数 | |
| freq_H | チャンネルのBPF最大周波数 | |
| freq_N | チャンネル数 | |
| Q | BFPのQ値
(各チャンネル共通) | |
| freq_lpf | LPFのカットオフ周波数
(各チャンネル共通) | |
| Q_lpf | LPFのQ値
(各チャンネル共通) | |
| wtype | 楽器側の波形 | |
| SAW | ノコギリ | |
| PULSE | 矩形 | |
| SIN | サイン | |
| carr_mix_type | 楽器側の混合指定 | |
| RAW | carr_freqs_seqそのまま | |
| FREQ | 「1/チャンネルの周波数」で混合 | |
| SAME | 楽器側もチャンネル群の周波数と同じにする | |
| 1-BASE | LPF群の出力結果から1つの基音の周波数を算出して使用する | |
| FILE | サウンド・ファイルを使用する | |
| carr_freq_seq | 楽器側の周波数の変化を指定 | |
| sample_freq_seq | carr_freq_seqのサンプルのメニュー | |
| base_rate | 算出した基音に乗じる値
(carr_mix_type が 1-BASE の場合のみ有効) | |
| base_offset | 算出した基音に足す値
(carr_mix_type が 1-BASE の場合のみ有効) | |
| carr_file | 楽器側のサウンド・ファイルを指定する
(carr_mix_type が FILE の場合のみ有効) | |
| use_modu | デバッグ用 | |
| mode_rate | 変調の強さ調整用 | |
| use_filter_n | 全チャンネルのフィルタ処理を一括化 | |
| use_bulk | 入力波形全体のフィルタ処理を一括化 | |
| play | 処理の実行と出力ファイルの再生 | |
python で numpy を使用。
GUI込みで 650行程度。
voco.py
#!/usr/bin/env python
import os
import math
import time
import numpy as np
from scipy import interpolate
import wx
import empty
import thr
import snd_ut
import cmd_ut
import wx_ut
import dbg
def filter_new( freq, Q, ftype, smp_freq ):
smp_t = 1.0 / smp_freq
w0 = 2 * math.pi * freq * smp_t
cos_w0 = math.cos( w0 )
alpha = math.sin( w0 ) / ( 2 * Q )
b0 = b1 = b2 = 0
if ftype == 'LPF':
b1 = 1 - cos_w0
b0 = b2 = b1 * 0.5
elif ftype == 'HPF':
b1 = -( 1 + cos_w0 )
b0 = b2 = -b1 * 0.5
elif ftype == 'BPF':
b0 = Q * alpha
b1 = 0
b2 = -b0
a0 = 1 + alpha
a1 = 2 * cos_w0
a2 = alpha - 1
div_a0 = 1.0 / a0 if a0 != 0 else 0
buf_i = [ 0, 0 ]
buf_o = [ 0, 0 ]
def trans( v ):
if a0 == 0:
return 0
out_v = ( b0 * v + b1 * buf_i[ -1 ] + b2 * buf_i[ -2 ] + a1 * buf_o[ -1 ] + a2 * buf_o[ -2 ] ) * div_a0
buf_i.pop( 0 )
buf_i.append( v )
buf_o.pop( 0 )
buf_o.append( out_v )
return out_v
return empty.new( locals() )
def filter_n_new( freqs, Qs, ftypes, smp_freq ):
n = len( freqs )
filters = list( map( lambda i: filter_new( freqs[ i ], Qs[ i ], ftypes[ i ], smp_freq ), range( n ) ) )
e = empty.new()
e.buf5 = np.zeros( ( n, 5 ) )
k5 = np.array( list( map( lambda fl: [ fl.b0, fl.b1, fl.b2, fl.a1, fl.a2 ], filters ) ) )
div_a0 = np.array( list( map( lambda fl: fl.div_a0, filters ) ) )
def trans( in_v ):
# in_v : single value or [ n ]
e.buf5[ : , 0 ] = in_v
out_v = np.sum( k5 * e.buf5, axis=-1 ) * div_a0
e.buf5 = np.roll( e.buf5, 1, axis=-1 )
e.buf5[ : , 3 ] = out_v
return out_v
b0 = k5[ : , 0 ].reshape( ( -1, 1 ) )
b1 = k5[ : , 1 ].reshape( ( -1, 1 ) )
b2 = k5[ : , 2 ].reshape( ( -1, 1 ) )
a1 = k5[ : , 3 ]
a2 = k5[ : , 4 ]
div_a0_ = div_a0.reshape( ( -1, 1 ) )
def trans_bulk( in_vs ):
# in_vs : [ n, m ]
m = in_vs.shape[ -1 ]
in_vs_1 = np.roll( in_vs, 1, axis=-1 )
in_vs_1[ : , 0 ] = 0
in_vs_2 = np.roll( in_vs_1, 1, axis=-1 )
in_vs_2[ : , 0 ] = 0
r = ( in_vs * b0 + in_vs_1 * b1 + in_vs_2 * b2 ) * div_a0_
r[ : , 1 ] += r[ : , 0 ] * a1 * div_a0
for i in range( 2, m ):
r[ : , i ] += ( r[ : , i - 1 ] * a1 + r[ : , i - 2 ] * a2 ) * div_a0
return r
return empty.add( e, locals() )
def voco_ch_new( freq, Q, freq_lpf, Q_lpf, smp_freq ):
bpf = filter_new( freq, Q, 'BPF', smp_freq )
lpf = filter_new( freq_lpf, Q_lpf, 'LPF', smp_freq )
def get( v_voice ):
v = bpf.trans( v_voice )
v = lpf.trans( abs( v ) )
return v
return empty.new( locals() )
def voco_new( freq_L, freq_H, freq_N, Q, freq_lpf, Q_lpf, smp_freq, use_filter_n ):
freqs = np.linspace( freq_L, freq_H, freq_N )
voco_chs = list( map( lambda freq: voco_ch_new( freq, Q, freq_lpf, Q_lpf, smp_freq ), freqs ) )
def get_v1( v_voice ):
vs = list( map( lambda voco: voco.get( v_voice ), voco_chs ) )
return np.array( vs )
n = len( freqs )
bpf_n = filter_n_new( freqs, [ Q ] * n, [ 'BPF' ] * n, smp_freq )
lpf_n = filter_n_new( [ freq_lpf ] * n, [ Q_lpf ] * n, [ 'LPF' ] * n, smp_freq )
def get_v2( v_voice ):
vs = bpf_n.trans( v_voice )
vs = lpf_n.trans( np.abs( vs ) )
return vs
get = get_v2 if use_filter_n else get_v1
def get_base( v_voice ):
vs = get( v_voice )
base = None
vs_sum = vs.sum()
if vs_sum != 0:
rate = vs / vs_sum
base = ( freqs * rate ).sum()
return ( vs, base )
def get_bulk( in_vs ):
in_vs = np.repeat( [ in_vs ], n, axis=0 )
vs = bpf_n.trans_bulk( in_vs )
vs = np.abs( vs )
return lpf_n.trans_bulk( vs )
return empty.new( locals() )
def wave_new( freq_init, wtype, smp_freq ):
e = empty.new()
e.enale = True
e.ph = 0
def set_freq( freq ):
e.enable = ( freq > 0 )
if e.enable:
e.freq = freq
def get_wave():
if not e.enable:
return 0
if wtype == 'PULSE':
return -1.0 if e.ph < 0.5 else 1.0
if wtype == 'SAW':
return e.ph * 2 - 1
if wtype == 'SIN':
return math.sin( 2 * math.pi * e.ph )
return 0
def get():
v = get_wave()
e.ph += e.freq / smp_freq
e.ph -= int( e.ph )
return v
set_freq( freq_init)
return empty.new( locals() )
def carr_file_new( smp_freq, smp_n, carr_file ):
carr_data = snd_ut.data_new( carr_file )
carr_smp_freq = carr_data.inf.r
carr_smp_n = carr_data.inf.smp_n
arr = carr_data.get_arr()
ch = carr_data.inf.c
if ch > 1:
arr = arr.reshape( ( -1, ch ) ).mean( axis=-1 )
def get_xs( smp_freq, smp_n ):
return np.linspace( 0, smp_n / smp_freq, smp_n, endpoint=False )
f_carr = interpolate.interp1d( get_xs( carr_smp_freq, carr_smp_n ), arr, bounds_error=False, fill_value=( 0, 0 ) )
xs = get_xs( smp_freq, smp_n ) # voice
carr_tail_sec = carr_smp_n / carr_smp_freq
xs -= carr_tail_sec * ( xs // carr_tail_sec ) # repeat
arr2 = f_carr( xs )
arr = arr2
e = empty.new()
e.i = 0
def get_mix():
v = 0
if e.i < smp_n:
v = arr[ e.i ]
e.i += 1
return v
def get_bulk():
return arr
return empty.add( e, locals() )
def carr_new( wtype, freqs_seq, mix_type, smp_freq, smp_n, carr_file ):
if mix_type == 'FILE':
return carr_file_new( smp_freq, smp_n, carr_file )
max_n = max( map( lambda fs: len( fs ), freqs_seq ) )
freqs_seq = np.array( list( map( lambda fs: ( fs + [ 0 ] * max_n )[ : max_n ], freqs_seq ) ) )
waves = list( map( lambda freq: wave_new( freq, wtype, smp_freq ), freqs_seq[ 0 ] ) )
waves_n = len( waves )
e = empty.new()
e.rates = np.ones( len( waves ) )
e.rates_freq = np.zeros( len( waves ) )
e.smp_i = 0
e.seq_i = 0
def fill_n( arr, n, full_v ):
return np.append( np.array( arr ), np.full( full_v, n ) )[ : n ]
def get_freqs_idx():
return int( len( freqs_seq ) * e.smp_i / smp_n )
def set_rates( rates ):
e.rates = fill_n( rates, waves_n, 0 )
def set_freqs( freqs ):
freqs = fill_n( freqs, waves_n, 0 )
for ( i, wave ) in enumerate( waves ):
freq = freqs[ i ]
wave.set_freq( freq )
e.rates_freq[ i ] = 1.0 / freq if freq > 0 else 0
def get_raw(): # []
return np.array( list( map( lambda wave: wave.get(), waves ) ) )
def mix( raw, rates ):
return ( raw * rates ).sum()
def get_mix():
raw = get_raw()
v = 0
if mix_type in ( 'RAW', '1-BASE' ):
v = raw.mean()
elif mix_type == 'FREQ':
v = mix( raw, e.rates_freq )
elif mix_type == 'SAME':
v = mix( raw, e.rates )
e.smp_i += 1
seq_i = get_freqs_idx()
if seq_i > e.seq_i:
e.seq_i = seq_i
if e.seq_i < len( freqs_seq ):
set_freqs( freqs_seq[ e.seq_i ] )
return v
def get_bulk():
# only raw mix
freqs_seq_n = len( freqs_seq )
nn = smp_n // freqs_seq_n
ns = [ nn ] * freqs_seq_n
ns[ -1 ] += smp_n - nn * freqs_seq_n
r = np.empty( 0 )
for ( i, n ) in enumerate( ns ):
set_freqs( freqs_seq[ i ] )
a = np.array( list( map( lambda i: get_raw().mean(), range( n ) ) ) )
r = np.append( r, a )
return r
set_freqs( freqs_seq[ 0 ] )
return empty.new( locals() )
def play_file( file_path ):
( name, ext ) = os.path.splitext( file_path )
if ext == ".mp3":
snd_ut.cvt( name, 'mp3', 'wav' )
file_path = name + ".wav"
sudo_pass = 'kondoh'
cmd = "echo {} | sudo -S play {}".format( sudo_pass, file_path )
cmd_ut.call( cmd )
def do_voco( prm ):
carr_freqs_seq = eval( prm.carr_freqs_seq )
voice_data = snd_ut.data_new( prm.voice_file )
smp_freq = voice_data.inf.r
smp_n = voice_data.inf.smp_n
arr = voice_data.get_arr()
voi_ch = voice_data.inf.c
if voi_ch > 1:
arr = arr.reshape( ( -1, voi_ch ) ).mean( axis=-1 )
voco = voco_new( prm.freq_L, prm.freq_H, prm.freq_N, prm.Q, prm.freq_lpf, prm.Q_lpf, smp_freq, prm.use_filter_n )
if prm.carr_mix_type == 'SAME':
carr_freqs_seq = [ voco.freqs ]
elif prm.carr_mix_type == '1-BASE':
carr_freqs_seq = [ [ 400 ] ]
carr = carr_new( prm.wtype, np.array( carr_freqs_seq ), prm.carr_mix_type, smp_freq, smp_n, prm.carr_file )
freqs = voco.freqs * prm.modu_rate
n = len( freqs )
if prm.use_filter_n or prm.use_bulk:
bpfs = filter_n_new( freqs, [ prm.Q ] * n, [ 'BPF' ] * n, smp_freq )
else:
bpfs = list( map( lambda freq: filter_new( freq, prm.Q, 'BPF', smp_freq ), freqs ) )
def f_modu( voice_v ):
if prm.carr_mix_type == '1-BASE':
( voco_out, base ) = voco.get_base( voice_v )
if base is not None:
carr.set_freqs( [ base * prm.base_rate + prm.base_offset ] )
elif prm.carr_mix_type == 'SAME':
voco_out = voco.get( voice_v )
carr.set_rates( voco_out )
else:
voco_out = voco.get( voice_v )
out = carr.get_mix()
if prm.use_modu:
if prm.use_filter_n:
out = bpfs.trans( out )
else:
out = np.array( list( map( lambda bpf: bpf.trans( out ), bpfs ) ) )
out = ( out * voco_out ).mean()
return out
if prm.use_bulk:
voco_out = voco.get_bulk( arr )
carr_out = carr.get_bulk()
carr_out = np.repeat( [ carr_out ], n, axis=0 )
carr_out = bpfs.trans_bulk( carr_out )
out = np.mean( carr_out * voco_out, axis=0 )
else:
out = np.array( list( map( f_modu, arr ) ) )
max_v = np.max( np.abs( out ) )
if max_v != 0:
out *= 0.8 / max_v
voice_data.save_arr( out, prm.out_file )
quit_ths = []
def gc():
while quit_ths:
th = quit_ths.pop( 0 )
th.stop()
def play_file_th( file_path, th ):
play_file( file_path )
quit_ths.append( th )
def gui_init( wxo ):
tc_voice_file = wxo.tc_file_sel( "voice/voice_sample_1.mp3" )
tc_out_file = wxo.tc_new( "/tmp/out.wav" )
def hdl_org_play( inf ):
th = thr.th_new( play_file_th, ( tc_voice_file.GetValue(), ), th_arg='append' )
th.start()
btn_org_play = wxo.button_new( 'org play', hdl_org_play )
tc_num_freq_L = wxo.tc_num_new( 500.0, qtz_exp='0.1' )
tc_num_freq_H = wxo.tc_num_new( 4000.0, qtz_exp='0.1' )
mn_int_freq_N = wxo.menu_int_new( 1, 20, v_init=4 )
tc_num_Q = wxo.tc_num_new( 3.0, qtz_exp='0.1' )
tc_num_freq_lpf = wxo.tc_num_new( 10.0, qtz_exp='0.1' )
tc_num_Q_lpf = wxo.tc_num_new( 0.7, qtz_exp='0.1' )
mn_wtype = wxo.menu_new( [ 'SAW', 'PULSE', 'SIN' ], init_str='SAW' )
def hdl_mn( inf ):
wxo = inf.wxo
L = wxo.L
s = inf.menu.lbl
if s == 'RAW':
tc_carr_freqs_seq.Enable()
mn_freqs_seq.Enable()
tc_num_base_rate.Disable()
tc_num_base_offset.Disable()
tc_carr_file.tc.Disable()
tc_carr_file.btn.Disable()
btn_carr_play.Disable()
elif s == 'FREQ':
tc_carr_freqs_seq.Enable()
mn_freqs_seq.Enable()
tc_num_base_rate.Disable()
tc_num_base_offset.Disable()
tc_carr_file.tc.Disable()
tc_carr_file.btn.Disable()
btn_carr_play.Disable()
elif s == 'SAME':
tc_carr_freqs_seq.Disable()
mn_freqs_seq.Disable()
tc_num_base_rate.Disable()
tc_num_base_offset.Disable()
tc_carr_file.tc.Disable()
tc_carr_file.btn.Disable()
btn_carr_play.Disable()
elif s == '1-BASE':
tc_carr_freqs_seq.Disable()
mn_freqs_seq.Disable()
tc_num_base_rate.Enable()
tc_num_base_offset.Enable()
tc_carr_file.tc.Disable()
tc_carr_file.btn.Disable()
btn_carr_play.Disable()
elif s == 'FILE':
tc_carr_freqs_seq.Disable()
mn_freqs_seq.Disable()
tc_num_base_rate.Disable()
tc_num_base_offset.Disable()
tc_carr_file.tc.Enable()
tc_carr_file.btn.Enable()
btn_carr_play.Enable()
mn_carr_mix_type = wxo.menu_new( [ 'RAW', 'FREQ', 'SAME', '1-BASE', 'FILE' ], hdl_mn, init_str='RAW' )
sample_freqs_seq = [
"[ [ 400, 500, 600 ], [ 400, 475 ,600 ] ]",
"[ [ 50 ], [ 200 ], [ 800 ], [ 200 ], [ 50 ] ]",
"[ [ 50, 500, 5000 ], [ 30, 300, 3000 ] ]",
"[ [ 100, 200, 300, 400, 500, 600, 800, 1000, 1200 ] ]",
]
tc_carr_freqs_seq = wxo.tc_new( sample_freqs_seq[ 0 ] )
def hdl_mn_freqs_seq( inf ):
s = inf.menu.lbl
tc_carr_freqs_seq.SetValue( s )
mn_freqs_seq = wxo.menu_new( sample_freqs_seq, hdl_mn_freqs_seq )
tc_num_base_rate = wxo.tc_num_new( 1.0, qtz_exp='0.01' )
tc_num_base_rate.Disable()
tc_num_base_offset = wxo.tc_num_new( 0, qtz_exp='0.1' )
tc_num_base_offset.Disable()
tc_carr_file = wxo.tc_file_sel( "kb/kb-1.mp3" )
tc_carr_file.tc.Disable()
tc_carr_file.btn.Disable()
def hdl_carr_play( inf ):
th = thr.th_new( play_file_th, ( tc_carr_file.GetValue(), ), th_arg='append' )
th.start()
btn_carr_play = wxo.button_new( 'carr play', hdl_carr_play )
btn_carr_play.Disable()
cbox_use_modu = wxo.checkbox_new( 'use_modu', init_stat=True )
tc_num_modu_rate = wxo.tc_num_new( 1.0, qtz_exp='0.1' )
cbox_use_filter_n = wxo.checkbox_new( 'use_filter_n' )
cbox_use_bulk = wxo.checkbox_new( 'use_bulk' )
def get_prm( wxo ):
prm = empty.new()
def set( name, pre='', method='GetValue', cast=None ):
w = getattr( wxo.L, pre + name )
if method:
f = getattr( w, method )
v = f()
else:
v = w # !
if cast:
v = cast( v )
setattr( prm, name, v )
set( 'voice_file', pre='tc_' )
set( 'out_file', pre='tc_' )
set( 'freq_L', pre='tc_num_', cast=float )
set( 'freq_H', pre='tc_num_', cast=float )
set( 'freq_N', pre='mn_int_', method='', cast=lambda w: wxo.menu_get( w ).v )
set( 'Q', pre='tc_num_', cast=float )
set( 'freq_lpf', pre='tc_num_', cast=float )
set( 'Q_lpf', pre='tc_num_', cast=float )
set( 'wtype', pre='mn_', method='GetStringSelection' )
set( 'carr_mix_type', pre='mn_', method='GetStringSelection' )
set( 'carr_freqs_seq', pre='tc_' )
set( 'base_rate', pre='tc_num_', cast=float )
set( 'base_offset', pre='tc_num_', cast=float )
set( 'carr_file', pre='tc_' )
set( 'use_modu', pre='cbox_' )
set( 'modu_rate', pre='tc_num_', cast=float )
set( 'use_filter_n', pre='cbox_' )
set( 'use_bulk', pre='cbox_' )
return prm
lbl_sec = wxo.label_new( "ww.ww sec" )
q_play = thr.que_new()
def th_f():
inf = q_play.get()
if th.quit_ev.is_set():
return
wx.CallAfter( inf.wxo.frame.Disable )
prm = get_prm( inf.wxo )
sta = time.time()
do_voco( prm )
sec = time.time() - sta
s = str( dbg.quantize( sec, '0.01' ) ) + " sec"
wx.CallAfter( lbl_sec.SetLabel, s )
wx.CallAfter( inf.wxo.frame.Enable )
play_file( prm.out_file )
wx.CallAfter( btn_replay.Enable )
th = thr.loop_new( th_f )
th.start()
def hdl_play( inf ):
q_play.put( inf )
btn_play = wxo.button_new( 'play', hdl_play )
btn_play.SetFocus()
def hdl_replay( inf ):
prm = get_prm( inf.wxo )
play_file( prm.out_file )
btn_replay = wxo.button_new( 'replay', hdl_replay )
btn_replay.Disable()
we = wxo.wp_exp
lsts = [
we( [ 'voice_file', we( tc_voice_file.tc, prop=1 ), tc_voice_file.btn, btn_org_play ] ),
we( [ 'out_file', we( tc_out_file, prop=1 ) ] ),
we( [ 'freq_L', tc_num_freq_L, 'freq_H', tc_num_freq_H,
'freq_N', mn_int_freq_N, 'Q', tc_num_Q ] ),
we( [ 'freq_lpf', tc_num_freq_lpf, 'Q_lpf', tc_num_Q_lpf ] ),
we( [ 'wtype', mn_wtype, 'carr_mix_type', mn_carr_mix_type ] ),
we( [ 'carr_freqs_seq', we( tc_carr_freqs_seq, prop=1 ) ], prop=1 ),
we( [ 'sample_freqs_seq', we( mn_freqs_seq ) ] ),
we( [ 'base_rate', tc_num_base_rate, 'base_offset', tc_num_base_offset ] ),
we( [ 'carr_file', we( tc_carr_file.tc, prop=1 ), tc_carr_file.btn, btn_carr_play ] ),
we( [ cbox_use_modu, '| modu_rate', tc_num_modu_rate ] ),
we( [ cbox_use_filter_n, cbox_use_bulk ] ),
we( [ we( btn_play, prop=1 ), lbl_sec, btn_replay ] ),
]
wxo.wrap_frame( lsts )
def quit():
th.quit_ev.set()
q_play.put( None )
th.stop()
wxo.L = empty.new( locals() )
def run():
wxo = wx_ut.new( 'voco', gui_init )
wxo.set_icon( "beat.jpg" )
wxo.main_loop()
wxo.L.quit()
if __name__ == "__main__":
run()
# EOF
pythonのユーティリティ・プログラム 2020冬 を使ってます。
| filter_new | フィルタ処理用クラス | trans( in_v ) | 変換 |
| trans_bulk( in_vs ) | データ全体を一括して変換 | ||
| voco_ch_new | ボコーダのチャンネル処理用のクラス | bpf = filter_new( ... ) | BPF |
| lpf = filter_new( ... ) | LPF | ||
| get( v_voice ) | LPF出力の取得 | ||
| voco_new | ボコーダ処理用のクラス | voco_chs = list( map( ... ) ) | チャンネル群のインスタンスを保持 |
| get( v_voice ) | 全チャンネルのLPF出力の取得 | ||
| get_base( v_voice ) | 全チャンネルのLPF出力と、そこから算出した基音の周波数の取得 | ||
| get_bulk( in_vs ) | 音声データ全体を入力して、全チャンネルのLPF出力全体を一括して取得 | ||
| wave_new | 楽器側波形生成用のクラス(単音) | set_freq( freq ) | 周波数を指定する |
| get() | 単音の波形を取得 | ||
| carr_new | 楽器側の波形生成用クラス(和音) | waves = list( map( ... ) ) | waveクラスのインスタンスを同時発声する和音数分を保持 |
| set_rates( rates ) | 和音を混合する割合の指定する | ||
| set_freqs( freqs ) | 和音の周波数を指定する | ||
| get_mix() | 混合した波形の取得 | ||
| get_bulk() | 混合した波形を一括して取得 | ||
| play_file | 音声データファイルを再生する | ||
| do_voco | GUIからパラメータを渡され、ボコーダ処理を実行する | ||
音声読み上げソフト 音読さん
| 周波数の変化 | SAW (ノコギリ波) | PULSE (矩形波) | SIN (サイン波) |
|---|---|---|---|
| [ [ 400, 500, 600 ], [ 400, 475 ,600 ] ] | carr_wav/saw.wav | carr_wav/pulse.wav | carr_wav/sin.wav |
| [ [ 50 ], [ 200 ], [ 800 ], [ 200 ], [ 50 ] ] | carr_wav/saw2.wav | carr_wav/pulse2.wav | carr_wav/sin2.wav |
(お嬢のキーボードを拝借して、適当に演奏しました ;-p)
| kb/kb-1.mp3 |
| kb/kb-2.mp3 |
| kb/kb-3.mp3 |
| kb/kb-4.mp3 |

| RAW (そのまま) | outs/out-1.wav | |||
| freq_N 20 | outs/out-11.wav | |||
| freq_lpf 2.0 | outs/out-12.wav | |||
| freq_lpf 100.0 | outs/out-13.wav | |||
| Q_lpf 0.2 | outs/out-14.wav | |||
| Q_lpf 1.5 | outs/out-15.wav | |||
| PULSE | outs/out-2.wav | |||
| sample_freq_seq 2つめ | outs/out-3.wav | |||
| sample_freq_seq 3つめ | outs/out-4.wav | |||
| sample_freq_seq 4つめ | outs/out-5.wav | |||
| carr_mix_type FREQ | outs/out-6.wav | |||
| carr_mix_type SAME | outs/out-7.wav | |||
| carr_mix_type 1-BASE | outs/out-8.wav | |||
| base_rate 0.2 , base_offset 500 | outs/out-9.wav | |||
| base_rate 0.05 , base_offset 300 | outs/out-10.wav | |||
| freq_N 3 | outs/out-19.wav | |||
| freq_N 2 | outs/out-20.wav | |||
| freq_N 1 | outs/out-21.wav | |||
| carr_mix_type SAME | freq_N 4 | wtype SAW | outs/out-24.wav | |
| wtype PULSE | outs/out-25.wav | |||
| wtype SIN | outs/out-26.wav | |||
| freq_N 20 | wtype SAW | outs/out-22.wav | ||
| wtype PULSE | outs/out-23.wav | |||
| wtype SIN | outs/out-27.wav | |||
| 楽器側のサウンド・ファイル | kb-1.wav | outs/out-100.wav | ||
| kb-2.wav | outs/out-101.wav | |||
| kb-3.wav | outs/out-102.wav | |||
| kb-4.wav | outs/out-103.wav | |||
| voice_file voice_sample_2.mp3 | outs/out-16.wav | |||
| sample_freq_seq 2つめ | outs/out-17.wav | |||
| carr_mix_type SAME | freq_N 4 | wtype SIN | outs/out-28.wav | |
| freq_N 20 | wtype SIN | outs/out-18.wav | ||
| 楽器側のサウンド・ファイル | kb-1.wav | outs/out-110.wav | ||
| kb-2.wav | outs/out-111.wav | |||
| kb-3.wav | outs/out-112.wav | |||
| kb-4.wav | outs/out-113.wav | |||
初期のボコーダの雰囲気を再現できて、とても懐かしいです。
python + numpy でフィルタ処理を試してみたが、、、遅い。
一括処理するのでは無く、もっと高速化してストリーミング処理できるようにしたい。
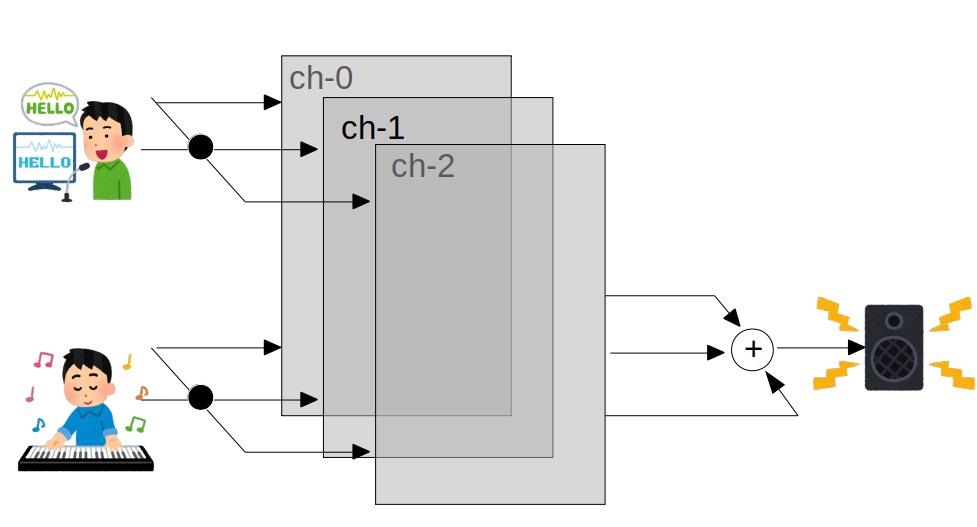
例えば、ライン入力の左右のチャンネルで、右側に音声、左側に楽器の入力を与えて、リアルタイムでスピーカから出力出来るように。